
Databricks Workflow Mistakes You’re Probably Making (And How to Fix Them)


Today, we will look at many of the most common pitfalls I've seen (and learned the hard myself a time or two) and how to fix them using best practices and rich features from the famous Data Intelligence platform!
1. Relying on Schedules to "orchestrate" Tasks
If you're like me and started using Databricks several years ago, you know that we could not always run multiple tasks in a job, much less orchestrate them. Often, data engineers need to break down a job into smaller steps or tasks, such as separating runtime dependencies, creating sequential and parallelized flow, or modularizing the code. A common mistake here is to build separate jobs and do a bit of cron schedule surgery to align these jobs so they run in a well-timed chain.
For example, we may build a data pipeline for a typical medallion architecture like so:

Meanwhile, other users created their own Apache Airflow servers to orchestrate the task. Fortunately, Databricks saw the need for robust orchestration features and now has several features built-in like multiple tasks in one job, task dependency (can run some tasks in parallel, or others in sequence), as well as conditional task runs (e.g., "run this task if XYZ happened"). The above example is wrong because it is too brittle--if any of the jobs takes too long, it "misses the train" for the next step. Likewise, if any of the jobs fails, there is no way for the other jobs to know to skip, so instead, they run unnecessarily, adding more cloud costs and potential alerts.
Using these features, we should only have one job for this use case. Each step is a Task configured to depend on the previous task completed. You can even refresh an SQL dashboard as one of your job tasks. However, at the time of this writing, Databricks only supports legacy SQL dashboards in this feature. Hopefully, it will add Lakeview Dashboards soon!
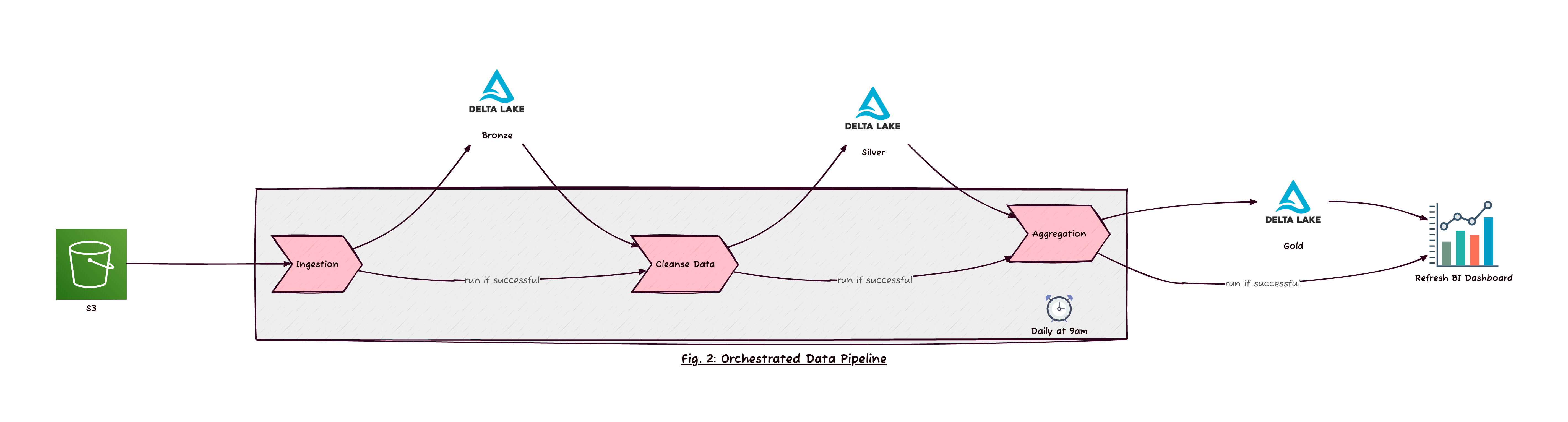
2. No Retries
Another common mistake is forgetting to configure max_retries on your Databricks job or its tasks. This is one of the easiest ways to add fault tolerance to your jobs and prevent transient issues from derailing critical workflows.

3. Let it Fail! Don't Swallow Exceptions
Retries are tremendous but only valid when the task actually "fails." This can be an oversight if you write code that catches exceptions and then sends them to a monitoring tool like Prometheus, CloudWatch, DataDog, etc.
cw = boto3.client('cloudwatch', region_name=region_name)
try:
df = spark.read.table("...")
# application code...
except Exception as e:
# Log error to CloudWatch
cw.put_metric(...)
# BAD!! Exception gets swallowed, and the job run is considered "successful."
CopyIf you want to instrument some error metrics this way, remember to re-throw the exception to allow Databricks to flag the task as "failed." This will trigger the retries, send notifications, and enable other features like conditional runs.
except Exception as e:
# Log error to CloudWatch
cw.put_metric(...)
# Re-throw to trigger job failure
raise e
Copy4. Not Using Notifications
One more easy victory in Databricks Workflows is the notifications. As of this writing, Databricks supports notifications via email, Slack, Microsoft Teams, Pagerduty, and generic Webhooks.
This often replaces convoluted monitoring solutions that require maintaining custom integrations or instrumentation in your code.
5. Git Folder vs. Git Integration for Notebooks
This may be a personal preference, but I strongly support it. If you are using "Git Folders" (formerly known as "Git Repos") in the Databricks workspace as the source for your notebook jobs, you should strongly consider switching to Git Integration.

What's the difference? Git folders are typically created by users and kept in their user directory on the workspace. More importantly, Git folders require explicitly pulling to receive changes; if you go this route, you should use the Databricks SDK from your CI/CD pipeline (e.g., GitHub Actions) to automate checking out new tags/branches or pulling changes from a main branch.
Jobs have built-in Git integration that relieves much of the stress. As shown in the picture above, this feature allows your job to effectively checkout the specified repo and Git ref when a run starts. If you point it at a main branch like 'main' or 'master,' you can achieve a minimal "CD" pipeline with zero CI/CD tooling!
6. Someone Leaves the Company, Jobs Fail?
If this one has burned you, I apologize, but we'll quickly learn how to avoid it in the future. Databricks makes it very easy to convert a prototype notebook into an automated/scheduled job—almost too easy. When users create jobs via the UI, they often leave the default "Run As" set to themselves and think nothing of it. The job runs fine for months or years; then, one day, that user leaves the company. The next day, your team is greeted by failure alerts and emails about missing data!
This is very common, as organizations take measures to close accounts and access as a regular part of employee exit policy. Our Databricks jobs may fail when they run as a user and rely on that user's access to Unity Catalog or notebooks in their workspace directory (although default settings in Databricks do not delete workspace files after the user is deactivated).
The solution concept is not unique to Databricks as this is a common problem in any platform as a service: Service Principals.
Honestly, this is one of the more tedious resources to manage in Databricks. As a Databricks Account Administrator, we can create new service principals easily, assign them access to workspaces, and create OAuth credentials for Machine-to-Machine (M2M) authentication in our applications. However, to combine this with the lesson learned in #5, we must use the OAuth credentials for the Service Principal to impersonate it and call the Databricks REST API POST /api/2.0/git-credentials. This effectively impersonates the Service Principal and creates Git Credentials for it.
Note: Databricks, if you are reading this, please consider adding the ability to manage Git credentials for Service Principals. You can upvote my idea on the Databricks Ideas Portal here!
Once you get it set up (hopefully not often), Service Principals make your jobs much more reliable to changes in org structure or employees leaving the company, and it enhances the overall security within your Unity Catalog by not over-exposing write access to individual users--your coworker, Bob, is not the one writing to that gold table, it's the daily-customer-report Job that writes to it 😉.
Conclusion
Let's wrap up. Databricks Workflows are awesome--one of the platform's most mature offerings in my opinion--and with these tips we can maximize their resiliency and usability.
I implore you to consider these lessons the next time you create a new Databricks Workflow. If you have tips and tricks for Databricks yourself, please let me know in the comments!
Follow for more content like this!